- 基础算法 - 回溯
- 相关题目
- 46. 全排列 - 力扣(LeetCode)
- 47. 全排列 II - 力扣(LeetCode)
- 78. 子集 - 力扣(LeetCode)
- 动态规划
- 回溯
- 17. 电话号码的字母组合 - 力扣(LeetCode)
- 39. 组合总和 - 力扣(LeetCode)
- 22. 括号生成 - 力扣(LeetCode)
- 79. 单词搜索 - 力扣(LeetCode)
- 131. 分割回文串 - 力扣(LeetCode)
- 51. N 皇后 - 力扣(LeetCode)
基础算法 - 回溯
回溯(Backtracking)作为一种重要的算法设计技术,在解决组合问题、排列问题以及搜索问题中广泛应用。其核心思想是通过试探和撤销的方式,在搜索过程中找到所有可能的解决方案。
回溯算法的主要特点包括:
- 递归:回溯算法通常采用递归方式实现,通过递归函数进行问题的求解。
- 试探:在每一步中,尝试不同的选择,进入下一步递归。
- 撤销:当当前选择不满足问题的要求时,撤销该选择并尝试其他可能的选择。
回溯算法适用于解决那些具有多个步骤和多个选择的问题,例如全排列、组合、子集、数独、八皇后等问题。其时间复杂度通常较高,但可以通过剪枝等优化方法提高效率。
回溯问题都可以通过画树图的方式理思路
相关题目
难度:中等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| class Solution {
public List<List<Integer>> res = new ArrayList<>();
public List<List<Integer>> permute(int []nums){
int num = nums.length;
boolean[] isUsed = new boolean[num];
List<Integer> tmp = new ArrayList<>();
int index = 0;
dfs(nums,num,index,isUsed,tmp);
return res;
}
void dfs(int[] nums, int num, int index, boolean[] isUsed, List<Integer> tmp){
if(index==num){
res.add(new ArrayList<>(tmp));
return;
}
for(int i=0;i<num;i++){
if(!isUsed[i]){
tmp.add(nums[i]);
index++;
isUsed[i] = true;
dfs(nums,num,index,isUsed,tmp);
index --;
isUsed[i] = false;
tmp.remove(tmp.size()-1);
}
}
}
}
|
主要涉及到栈的深度优先遍历,回溯所需要的depth(index)、状态记录(isUsed)…
还要注意到java的参数引用传递
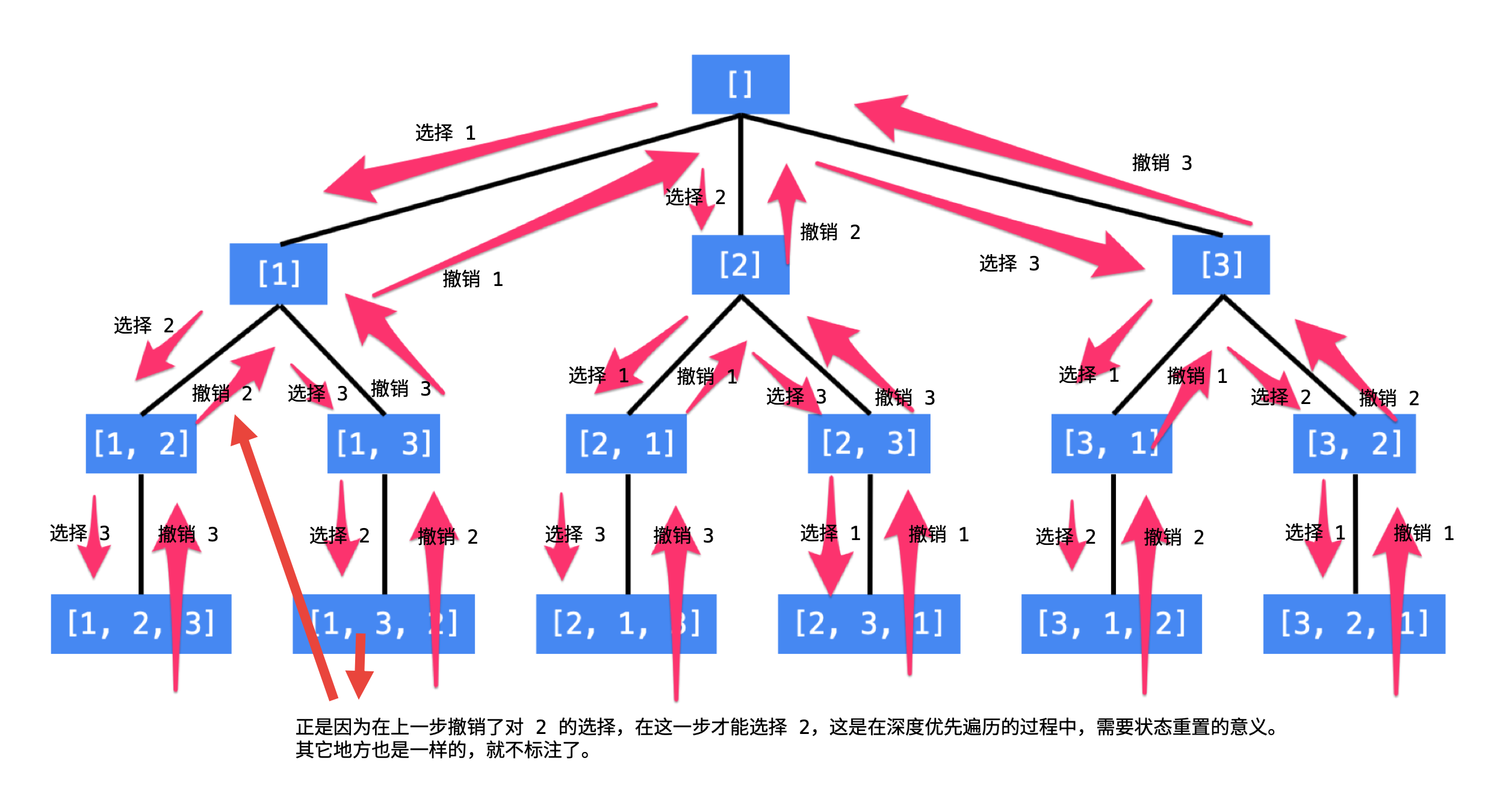
难度:中等
画数图会发现,只要在每一层保证重复的元素只用一次即可。
可以用哈希表来实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| class Solution {
public List<List<Integer>> permuteUnique(int[] nums) {
List<List<Integer>> res = new ArrayList<>();
List<Integer> tmp = new ArrayList<>();
int[] state = new int[nums.length];
int count = 0;
dfs(res,tmp,nums,state,0);
return res;
}
private void dfs(List<List<Integer>> res,List<Integer> tmp,int[] nums,int[] state,int count){
HashSet<Integer> map = new HashSet<>();
if(count==nums.length){
res.add(new ArrayList<>(tmp));
}
for(int i=0;i<nums.length;i++){
if(state[i]==0){
if(map.contains(nums[i])) continue;
else map.add(nums[i]);
state[i]=1;
tmp.add(nums[i]);
dfs(res,tmp,nums,state,count+1);
tmp.remove(count);
state[i]=0;
}
}
}
}
|
难度:中等
动态规划
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| class Solution {
private List<List<Integer>> res = new ArrayList<>();
public List<List<Integer>> subsets(int[] nums){
res.add(new ArrayList<>());
int num = nums.length;
for(int i = 0; i<num; i++){
int size = res.size();
System.out.println(size);
System.out.println(res);
for(int j = 0; j<size; j++){
List<Integer> new_t = new ArrayList<>(res.get(j));
new_t.add(nums[i]);
res.add(new ArrayList<>(new_t));
}
}
return res;
}
}
|
使用了动态规划的思想,如果当前数组为[1,2,3],dp[0]初始状态为空集,dp[1]为[]加上[1],
dp[2] = dp[1] + new,而这个new就等于以前的dp[1]中的所有子集加上这个新的2。
回溯
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| class Solution {
List<Integer> t = new ArrayList<Integer>();
List<List<Integer>> ans = new ArrayList<List<Integer>>();
public List<List<Integer>> subsets(int[] nums) {
dfs(0, nums);
return ans;
}
public void dfs(int cur, int[] nums) {
if (cur == nums.length) {
ans.add(new ArrayList<Integer>(t));
return;
}
t.add(nums[cur]);
dfs(cur + 1, nums);
t.remove(t.size() - 1);
dfs(cur + 1, nums)
}
}
|
因为每一个元素其实有两个状态,被选中或者未被选中,我们依次dfs即可。
可以想象成一个二叉树,每一层代表每一个元素,左子树代表选中,右子树代表未选中,从根节点到叶子节点的路径就为一个子集。
难度:中等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| public List<String> letterCombinations(String digits) {
HashMap<Character,String> map = new HashMap<Character,String>();
map.put('2', "abc");
map.put('3', "def");
map.put('4', "ghi");
map.put('5', "jkl");
map.put('6', "mno");
map.put('7', "pqrs");
map.put('8', "tuv");
map.put('9', "wxyz");
ArrayList<String> res = new ArrayList<>();
if(digits.equals("")){
return res;
}
dfs(res,map,digits,0,new StringBuffer());
return res;
}
public void dfs(List<String> res,HashMap<Character,String> map,String digits, int index, StringBuffer tmp){
if(index == digits.length()){
res.add(tmp.toString());
return;
}
char digit = digits.charAt(index);
String letters = map.get(digit);
int letterLen = letters.length();
for(int i=0;i<letterLen;i++){
tmp.append(letters.charAt(i));
dfs(res,map,digits,index+1,tmp);
tmp.deleteCharAt(index);
}
}
|
回溯的精髓就在于 回退之后的状态改变
也就是递归之后需要做和递归之前相反的事情
难度:中等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| class Solution {
List<List<Integer>> res = new ArrayList<>();
public List<List<Integer>> combinationSum(int[] candidates, int target) {
List<Integer> tmp = new ArrayList<>();
for(int i = 0;i<candidates.length;i++){
tmp.add(candidates[i]);
dfs(candidates,target,tmp, candidates[i],i);
tmp.remove(tmp.size()-1);
}
return res;
}
private void dfs(int[] candidates, int target,List<Integer> tmp,int sum,int pos){
if(sum==target){
res.add(new ArrayList<>(tmp));
return;
}
if(sum>target){
return;
}
for(int i=pos;i<candidates.length;i++){
tmp.add(candidates[i]);
dfs(candidates,target,tmp,sum+candidates[i],i);
tmp.remove(tmp.size()-1);
}
}
}
|
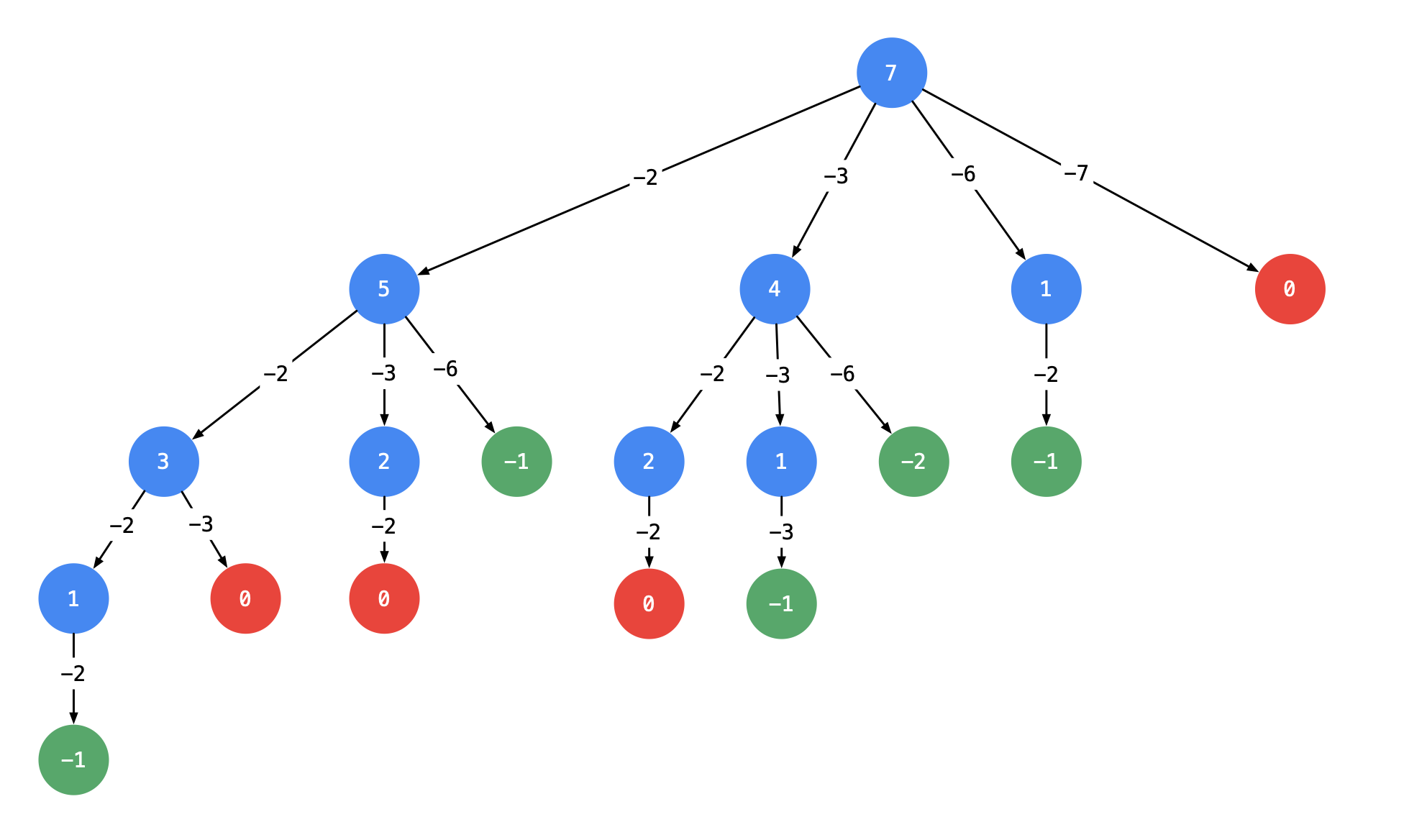
题目告诉了给出的nums数组中的元素是不重复的(而且还是按照从小到大的顺序的)
未考虑去重:
考虑去重:
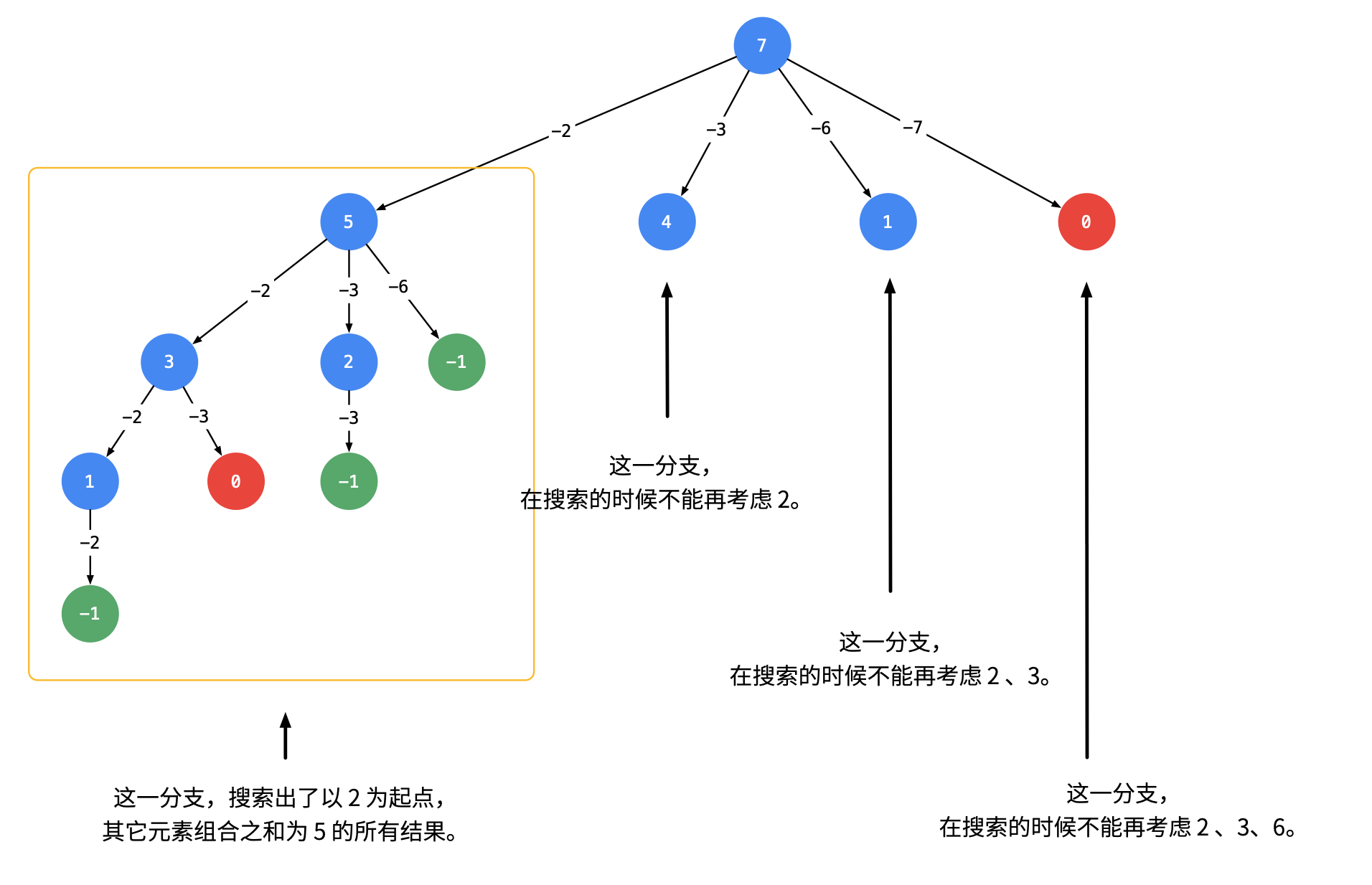
难度:中等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| class Solution {
List<String> res = new ArrayList<>();
public List<String> generateParenthesis(int n) {
StringBuffer sb = new StringBuffer();
dfs(n,n,sb);
return res;
}
private void dfs(int left,int right,StringBuffer sb){
if(left==0&&right==0){
res.add(sb.toString());
return;
}
if(left>0){
sb.append('(');
dfs(left-1,right,sb);
sb.deleteCharAt(sb.length()-1);
}
if(left<right){
sb.append(')');
dfs(left,right-1,sb);
sb.deleteCharAt(sb.length()-1);
}
}
}
|
可以想象成二叉树,根节点往左拐就是增加一个左括号,往右拐增加一个右括号,找到满足合法括号的路径。
在这里sb相当于栈。
难度:中等
二维的dfs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| class Solution_exist_redo {
boolean res = false;
int[][] dr = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
boolean[][] state;
public boolean exist(char[][] board, String word) {
state = new boolean[board.length][board[0].length];
int idx = 0;
int needChar = word.charAt(idx);
for (int i = 0; i < board.length; i++) {
for (int j = 0; j < board[0].length; j++) {
if (board[i][j] == needChar) {
state[i][j] = true;
dfs(board, word, idx + 1, i, j);
state[i][j] = false;
if(res) return true;
}
}
}
return res;
}
private void dfs(char[][] board, String word, int idx, int x, int y) {
if (idx == word.length()) {
res = true;
return;
}
for (int i = 0; i < 4; i++) {
if (res) return;
int nextX = x + dr[i][0];
int nextY = y + dr[i][1];
if (nextX < 0 || nextX >= board.length)
continue;
if (nextY < 0 || nextY >= board[0].length)
continue;
if (state[nextX][nextY])
continue;
if (board[nextX][nextY] != word.charAt(idx))
continue;
state[nextX][nextY] = true;
dfs(board, word, idx + 1, nextX, nextY);
state[nextX][nextY] = false;
}
}
}
|
但是dfs回溯的思想是一样的。
难度:中等(较难)
要先理解怎么判断回文字符串(动态规划),然后回溯寻找所有可能的分割方案
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| class Solution {
List<List<String>> res;
boolean[][] dp;
List<String> tmp;
public List<List<String>> partition(String s) {
res = new ArrayList<>();
tmp = new ArrayList<>();
int len = s.length();
dp = new boolean[len][len];
for (int i = 0; i < len; i++)
Arrays.fill(dp[i], true);
for (int i = len - 1; i >= 0; i--) {
for (int j = i + 1; j < len; j++) {
dp[i][j] = dp[i + 1][j - 1] && (s.charAt(i) == s.charAt(j));
}
}
dfs(s,0);
return res;
}
private void dfs(String s, int cur) {
if (cur == s.length()) {
res.add(new ArrayList<>(tmp));
return;
}
for (int i = cur; i < s.length(); i++) {
if (dp[cur][i]) {
tmp.add(s.substring(cur,i+1));
dfs(s,i+1);
tmp.remove(tmp.size()-1);
}
}
}
}
|
动态规划 + 回溯
核心思路
- 动态规划预处理:首先使用动态规划(DP)来预处理字符串
s,确定每个子串是否为回文。这部分预处理将帮助我们在回溯时快速判断子串是否为回文,从而减少不必要的重复计算。
- 回溯(DFS):然后使用回溯(深度优先搜索,DFS)来尝试所有可能的分割方式。每当发现一个合法的回文子串时,就递归地继续分割剩余的字符串,直到处理完整个字符串。
以aabb为例:
1
2
3
4
5
6
7
8
9
10
11
| ""
/ \
"a" "aa"
/ \ \
"a" "ab" "b"
/ \ (不合法) \
"b" "bb" "b"
/ \ (空)
"b" "b"
/ (空)
(空)
|
难度:困难
掌握了dfs的核心之后这个题就变得非常简单了,本题最复杂的点就是如何对访问过的点做标记。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
| class Solution {
List<List<Integer>> ans = new ArrayList<>();
List<Integer> path = new ArrayList<>();
public List<List<String>> solveNQueens(int n) {
int[][] state = new int[n][n];
dfs(0, state);
List<List<String>> res = new ArrayList<>();
for (int i = 0; i < ans.size(); i++) {
path = ans.get(i);
List<String> tmp = new ArrayList<>();
for (int j = 0; j < n; j++) {
StringBuffer stringBuffer = new StringBuffer();
int pos = path.get(j);
for (int k = 0; k < n; k++) {
if (k == pos) {
stringBuffer.append('Q');
} else {
stringBuffer.append('.');
}
}
tmp.add(stringBuffer.toString());
}
res.add(new ArrayList<>(tmp));
}
return res;
}
private void mark(int i, int j, int[][] state) {
int n = state.length;
for (int k = 0; k < n; k++) {
state[k][j]++;
state[i][k]++;
}
for (int k = -n + 1; k < n; k++) {
if ((0 <= i + k) && (0 <= j + k) && (i + k < n) && (j + k < n)) {
state[i + k][j + k]++;
}
if ((0 <= i - k) && (0 <= j + k) && (i - k < n) && (j + k < n)) {
state[i - k][j + k]++;
}
}
}
private void unMark(int i, int j, int[][] state) {
int n = state.length;
for (int k = 0; k < n; k++) {
state[k][j]--;
state[i][k]--;
}
for (int k = -n + 1; k < n; k++) {
if ((0 <= i + k) && (0 <= j + k) && (i + k < n) && (j + k < n)) {
state[i + k][j + k]--;
}
if ((0 <= i - k) && (0 <= j + k) && (i - k < n) && (j + k < n)) {
state[i - k][j + k]--;
}
}
}
private void dfs(int cur, int[][] state) {
int n = state.length;
if (cur == n) {
ans.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < n; i++) {
if (state[cur][i] == 0) {
mark(cur, i, state);
path.add(i);
dfs(cur + 1, state);
path.remove(path.size() - 1);
unMark(cur, i, state);
}
}
}
}
|
和前面的回溯题没什么不同,就是标记元素的方式改变了。Mark()与UnMark()
