
Jay1an🎈
I am who I am.
Google Hacking
Google Hacking
Google Hacking就是利用搜索引擎强大的搜索功能,选用搜索语法和特殊的搜索关键字,将隐藏在目标网站中的不恰当配置信息和后门信息找出来。
基本语法
- and :逻辑与
- or :;逻辑或
- +:强制包含搜索项
- -:逻辑非
- “关键词”:完整匹配
- *?:通配符
高级搜索
- site:搜索具体服务器或域名的网页
- filetype:搜索特定类型的文件
- intitle:搜索网页标题
- inurl:搜索URL
- intext:搜索正文
- link:搜索连接到指定网页的网页
- allintitle:用法和intitle类似,但可以指定多个词
这些方法可以互相可以组合。
附:Filetype所支持的文件类型
• Adobe Portable Document Format (pdf)
• Adobe PostScript (ps)
• Lotus 1-2-3 (wk1, wk2, wk3, wk4, wk5, wki, wks, wku)
• Lotus WordPro (lwp)
• MacWrite (mw)
• Microsoft Excel (xls)
• Microsoft PowerPoint (ppt)
• Microsoft Word (doc)
• Microsoft Works (wks, wps, wdb)
• Microsoft Write (wri)
• Rich Text Format (rtf)
• Text (ans, txt)
实例
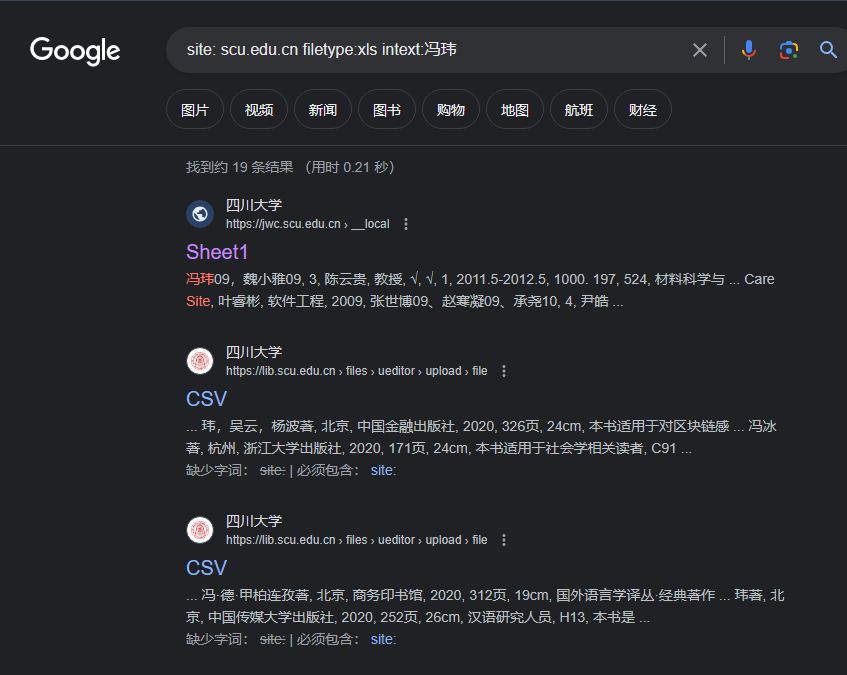
实例1:site、filetype、intext 配合
1 | site: scu.edu.cn filetype:xls intext:冯玮 |
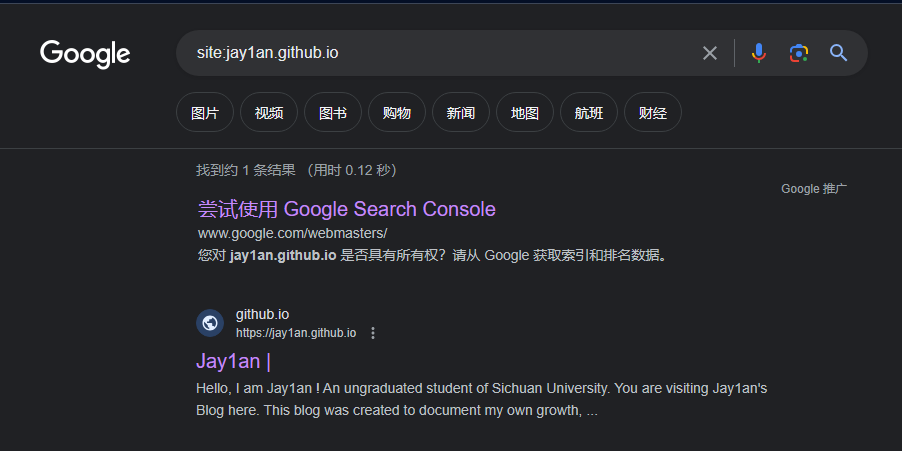
实例2:google搜索自己的blog是否被收录
网络攻防技术课程实验–>域名信息收集工具
实验要求
- 支持百度搜索引擎的域名提取,其中从百度搜索引擎提取的域名需为真实域名,而非百度的域名跳转链接。
- 可扩充其他功能,比如域名所在的标题等信息。
python代码的实现
1 | import requests |
运行结果:
1 | https://help.douban.com: 帮助中心 |